Automated Document Classification - USAID DEEM
Planted October 1, 2022
Automated document classification has become a key topic in Natural Language Processing (NLP) due to the rapid expansion of digital databases. However, a model that performs well for one classification task may yield weaker results on another dataset because of variations in data characteristics. Therefore, training multiple algorithms and evaluating their performance is essential to optimize results.
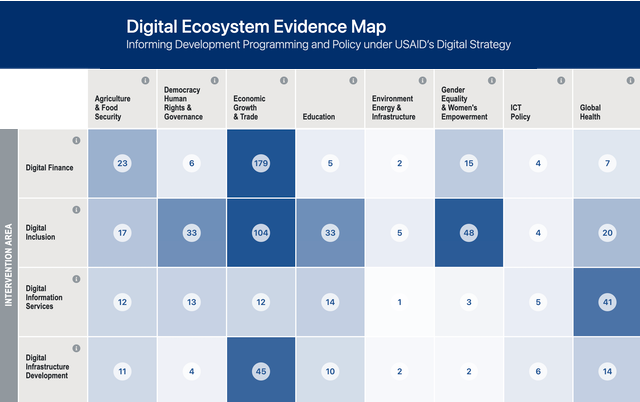
This project focuses on the USAID DEEM database, a live repository that enables users to search for information on digital development interventions around the world. (update: this site is currently unavailable)
Currently, document classification within the evidence map is performed manually by volunteers. The objective of this project is to automate this process, thereby minimizing human intervention and improving efficiency.
The following objectives have been set in order to accomplish the overall aim and the purpose of the study.
- To evaluate approaches in handling class imbalanced data in emerging fields
- To develop new models using ML and DL algorithms to classify digital reports
- To compare the performance of different models in multi-class classification of digital reports
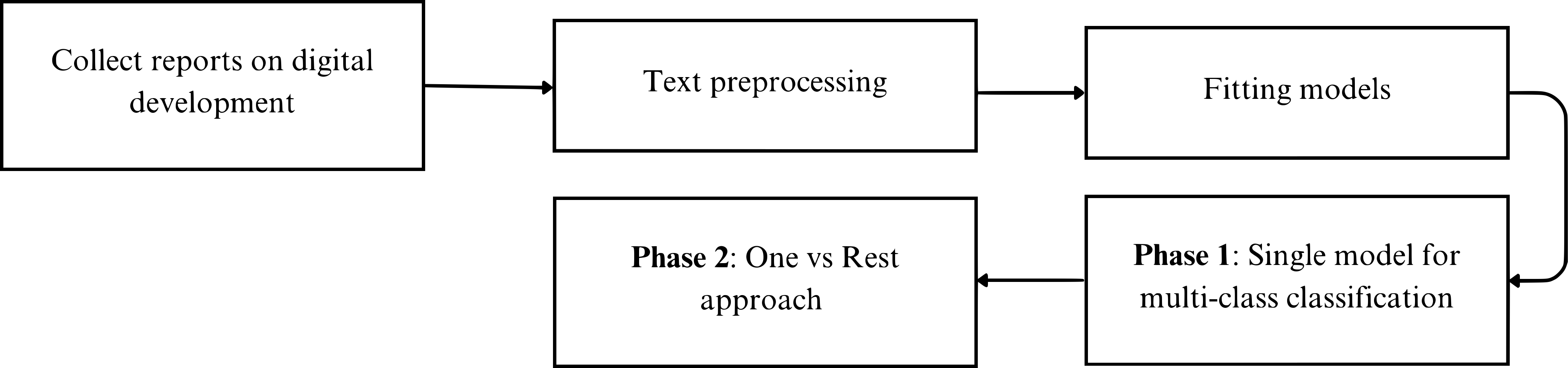
The proposed workflow is as follows:
Publications:
Comparing the Performance of LLMs in RAG-Based Question-Answering: A Case Study in Computer Science Literature conference paper
A One vs Rest Approach for Multi-class Document Classification poster