select a project to see it grow 🌾
Projects
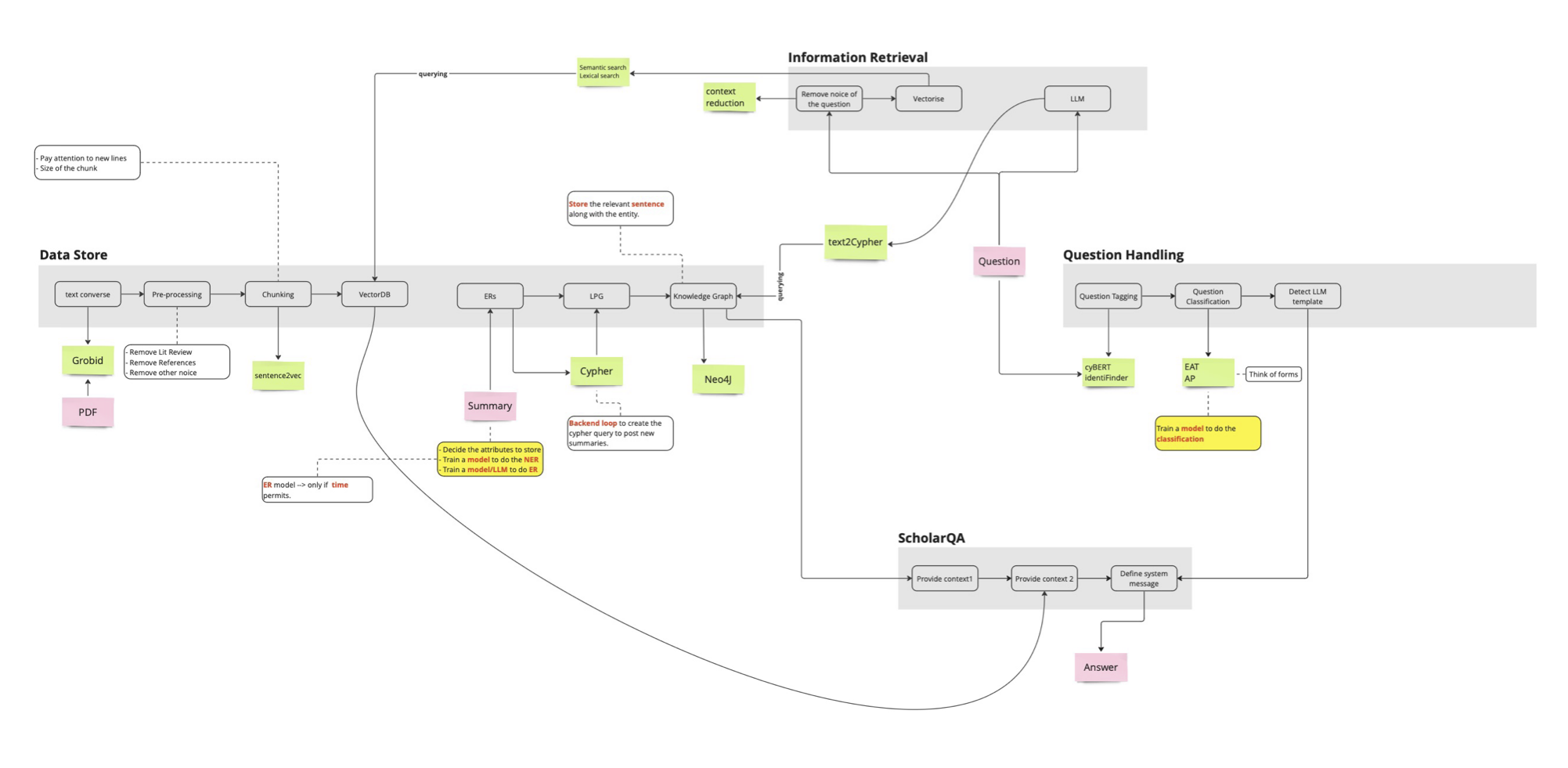
ScholarQA
With the introduction of OpenAI’s ChatGPT in 2022, the world experienced a major shift, and Large Language Models (LLMs) began emerging at an elevated pace.
Amid this rapid development, Retrieval-Augmented Generation (RAG) became a key concept in the spotlight. RAG is a technique designed to enhance the accuracy of LLM responses by allowing them to access and retrieve information from external knowledge sources.
Through ScholarQA we hope to study:
the performance of various open-source LLMs (LLaMa-2-7b-chat, Mistral-7b-instruct, Falcon-7b-instruct and Orca-mini-v3-7b) when integrated with RAG the importance of vectorizing data before feeding it into the RAG pipeline how integrating knowledge graphs can further improve the quality and accuracy of LLM responses Below is the proposed pipeline to test performance of LLMs when integrated with RAG :
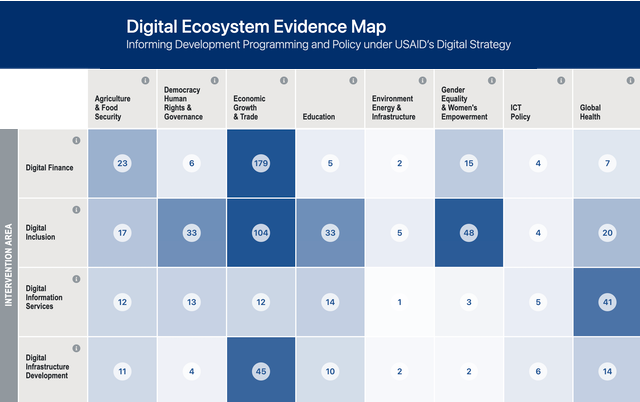
Automated Document Classification - USAID DEEM
Automated document classification has become a key topic in Natural Language Processing (NLP) due to the rapid expansion of digital databases. However, a model that performs well for one classification task may yield weaker results on another dataset because of variations in data characteristics. Therefore, training multiple algorithms and evaluating their performance is essential to optimize results.
This project focuses on the USAID DEEM database, a live repository that enables users to search for information on digital development interventions around the world. (update: this site is currently unavailable)