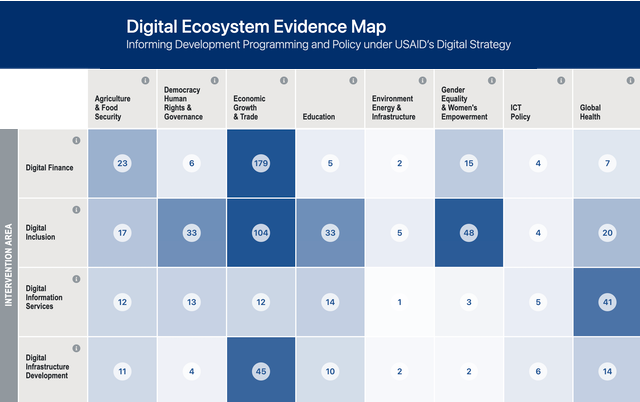
ScholarQA
Planted March 2, 2024
With the introduction of OpenAI’s ChatGPT in 2022, the world experienced a major shift, and Large Language Models (LLMs) began emerging at an elevated pace.
Amid this rapid development, Retrieval-Augmented Generation (RAG) became a key concept in the spotlight. RAG is a technique designed to enhance the accuracy of LLM responses by allowing them to access and retrieve information from external knowledge sources.
Through ScholarQA we hope to study:
- the performance of various open-source LLMs (LLaMa-2-7b-chat, Mistral-7b-instruct, Falcon-7b-instruct and Orca-mini-v3-7b) when integrated with RAG
- the importance of vectorizing data before feeding it into the RAG pipeline
- how integrating knowledge graphs can further improve the quality and accuracy of LLM responses
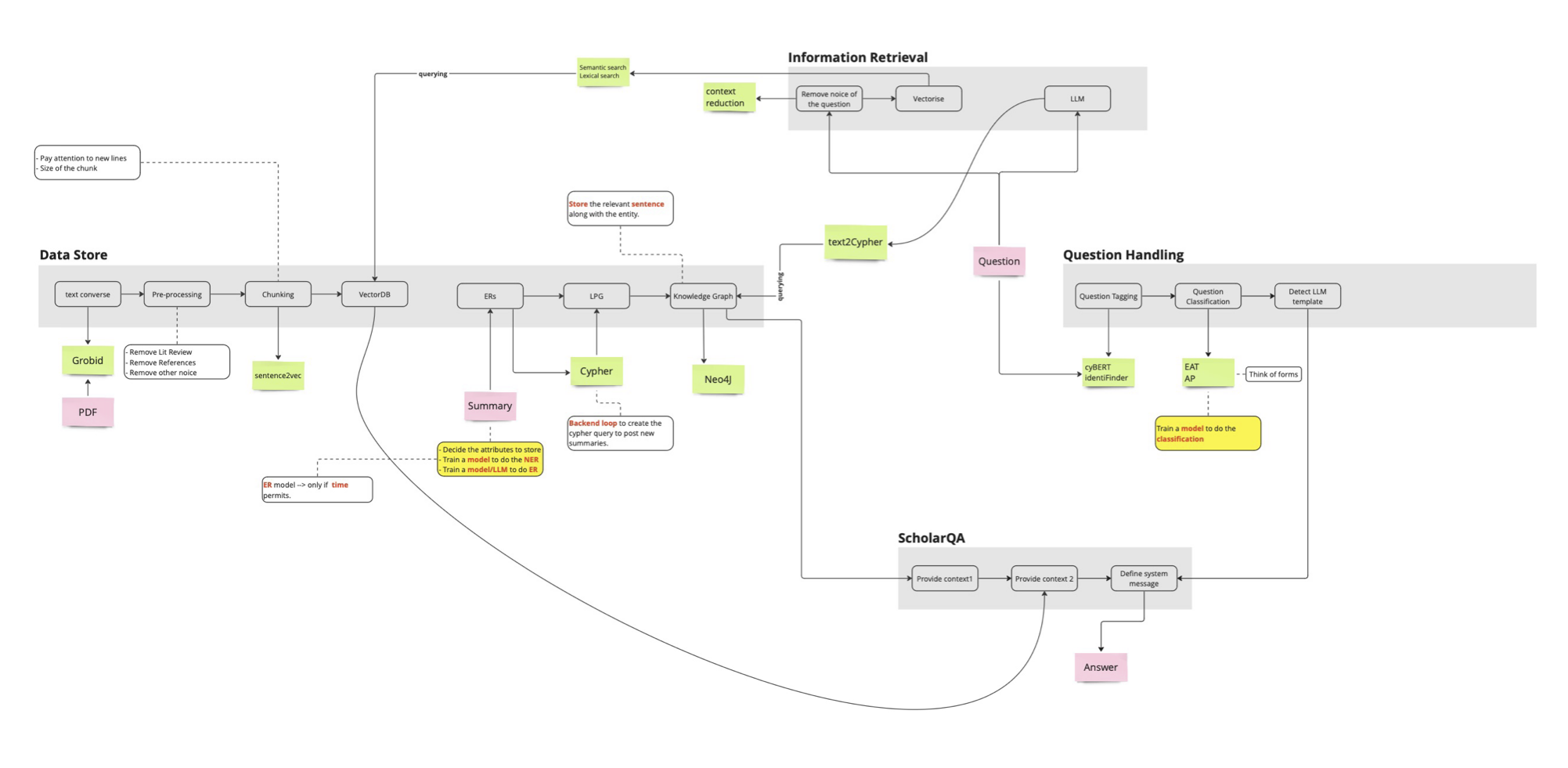
Below is the proposed pipeline to test performance of LLMs when integrated with RAG :

Publications:
- Comparing the Performance of LLMs in RAG-Based Question-Answering: A Case Study in Computer Science Literature conference paper